
The high memory bandwidth and parallel processing abilities of GPU cards mean that GPU computing can provide significant simulation speed advantages over conventional CPU computing. A series of comparative analyses were carried out to test the performance of NVIDIA’s Quadro GP100 and the brand new GV100 device, pictured below in Figure 1. These tests were performed using various models which represent typical applications that are simulated in the CST STUDIO SUITE® Time-Domain Solver.

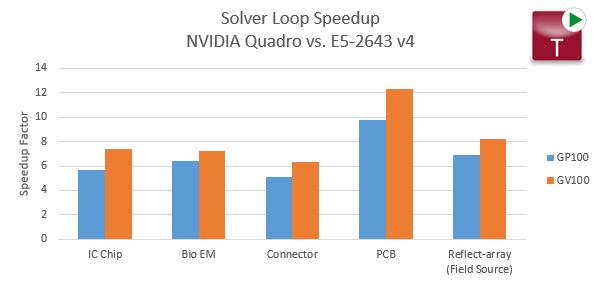
An initial study was done to compare the Quadro GP100 and Quadro GV100 against a high-end CPU model of the Intel Xeon Broadwell family. The CPU vs. GPU performance in Figure 2 shows that the NVIDIA Quadro devices can provide a significant speed-up to the Time-Domain Solver Loop*. On average, the latest GV100 model is shown to perform about 8 times faster than a high-end CPU; the performance of the GP100 model is not too far behind with an average speed-up factor around 7.
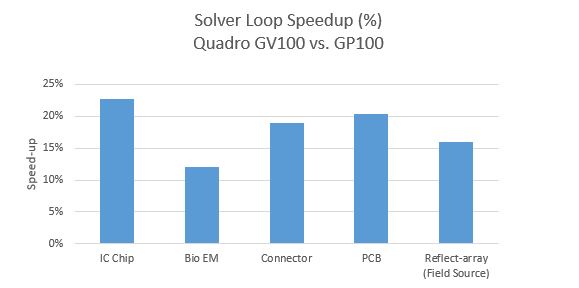
In another test, a direct comparison of the GP100 vs. GV100 was performed. The benchmark results shown in Figure 3 illustrate the GV100 performs about 20% faster than the GP100 device. This is in-line with what is expected, since the solver speed-up tends to be proportional to the difference in memory bandwidth of the GPU devices. The new Quadro GV100 device has an impressive memory bandwidth specification of 900GB/s vs. the GP100 at 732GB/s.
In parallel to their computational acceleration capabilities, Quadro series GPU cards can be utilized for their accelerated graphics capabilities; this means there is no requirement for an additional adapter. Quadro cards are specifically dedicated to CAD/CAE applications and well tested with CST STUDIO SUITE, making them the recommended option for display. They are also a particularly interesting option for those who are interested in a GPU dedicated for a workstation over a server-class system. Since these devices are actively cooled, they can be installed into a workstation chassis, which tends to be a more cost efficient option for simulations which can be solved within the resources of a single system.
Along with high memory bandwidth and parallelization capabilities, NVIDIA Quadro GPU devices have many additional noteworthy features. For instance, select Quadro cards can be utilized for the CST STUDIO SUITE double-precision solvers due to their powerful performance capabilities in this aspect. The Quadro GP100 and GV100 cards have fast double-precision performance at 5.2TFLOPs and 7.4TFLOPS respectively. The new Quadro GV100 also provides a significant increase in GPU RAM at 32GB making it very suitable for larger and more demanding tasks, which have not been possible for single GPU devices thus far.
NVIDIA just announced the release of the NVIDIA Quadro GV100 at the end of Q1 in 2018. This device is scheduled to be supported in CST STUDIO SUITE 2018 Service Pack 4 for the Time Domain solver. Full support of the GV100 for all GPU-empowered solvers will become available in the next major release. GPU-empowered solvers consist of: Transient FIT & TLM, Particle-in-Cell, Asymptotic, Integral-Equation, Multilayer and Conjugate Heat Transfer solvers. The NVIDIA Quadro GP100 device, which was also used in this study, has been fully supported since CST STUDIO SUITE 2017 Service Pack 2.
To learn more about CST STUDIO SUITE®, see website.
*Note that the solver loop time is not a representation of the total simulation time. The solver loop is the main, and most compute intensive phase of a time-domain simulation. The solver is the only phase of the simulation which takes advantage of GPU computation.
Melissa Reis, Application Engineer, CST of America



